BibTeX
@inproceedings{10.1007/978-3-031-88717-8_2,
author = {Abootorabi, Mohammad Mahdi and Asgari, Ehsaneddin},
title = {CLASP: Contrastive Language-Speech Pretraining for Multilingual Multimodal Information Retrieval},
year = {2025},
isbn = {978-3-031-88716-1},
publisher = {Springer-Verlag},
address = {Berlin, Heidelberg},
url = {https://doi.org/10.1007/978-3-031-88717-8_2},
doi = {10.1007/978-3-031-88717-8_2},
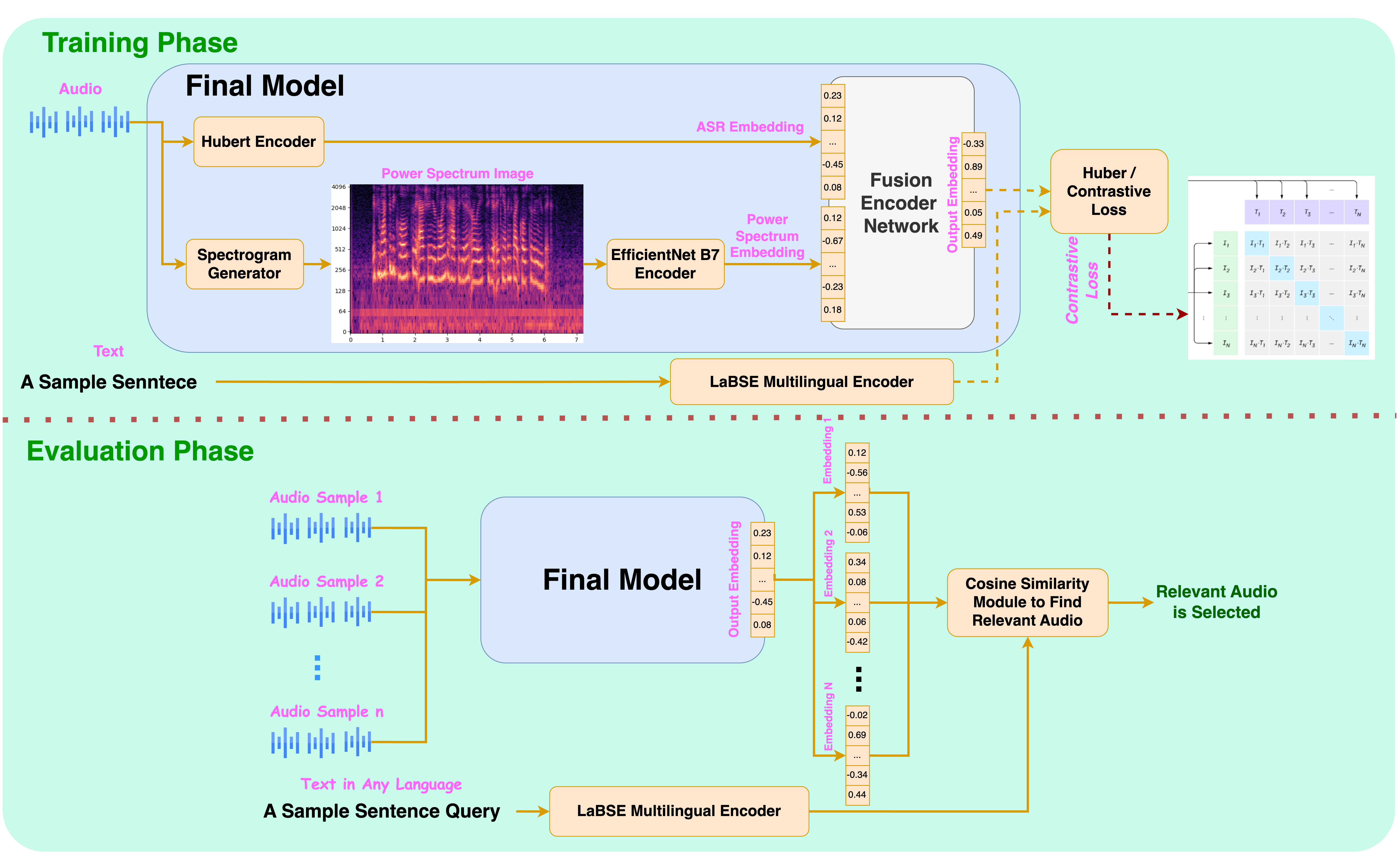
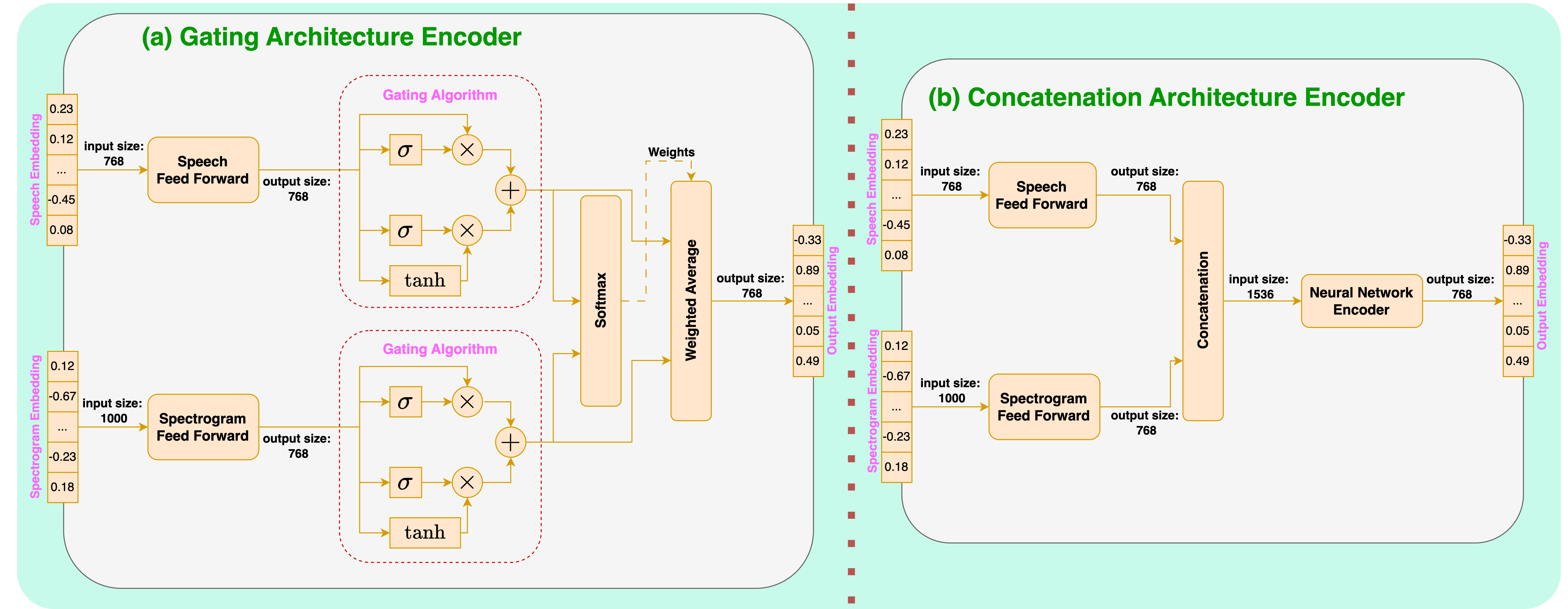
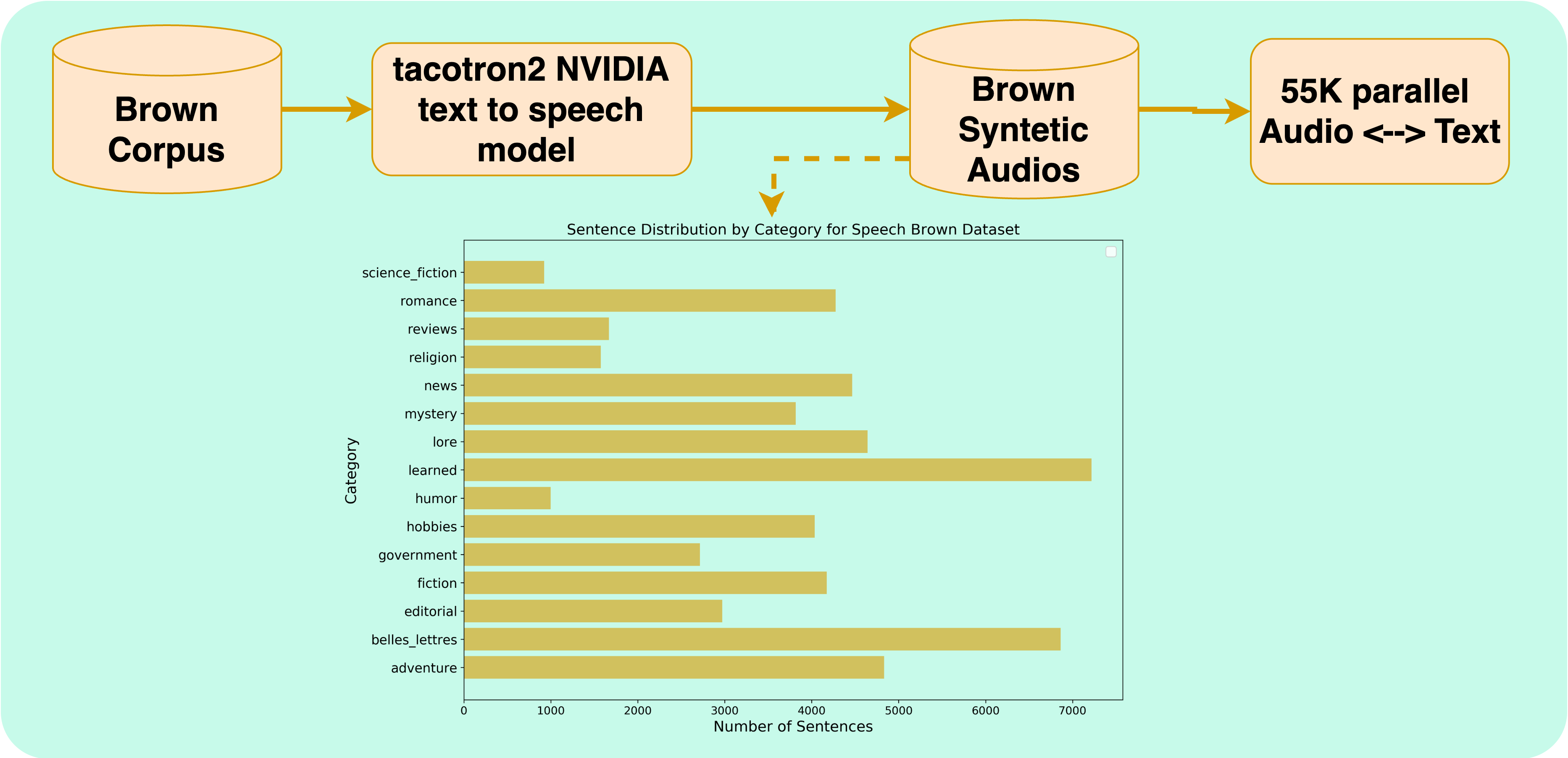
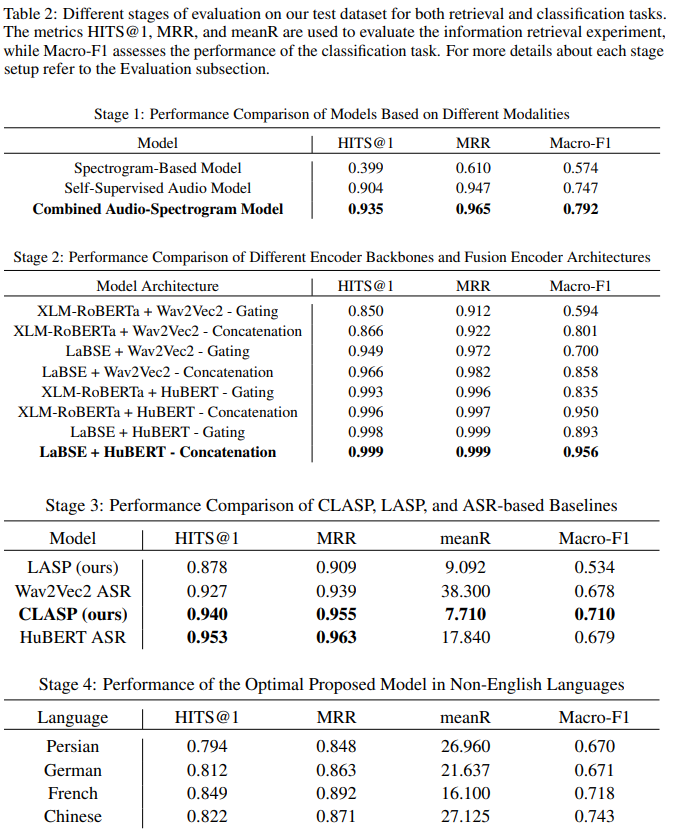
abstract = {This study introduces CLASP (Contrastive Language-Speech Pretraining), a multilingual, multimodal representation tailored for audio-text information retrieval. CLASP leverages the synergy between spoken content and textual data. During training, we utilize our newly introduced speech-text dataset, which encompasses 15 diverse categories ranging from fiction to religion. CLASP’s audio component integrates audio spectrograms with a pre-trained self-supervised speech model, while its language encoding counterpart employs a sentence encoder pre-trained on over 100 languages. This unified lightweight model bridges the gap between various modalities and languages, enhancing its effectiveness in handling and retrieving multilingual and multimodal data. Our evaluations across multiple languages demonstrate that CLASP establishes new benchmarks in HITS@1, MRR, and meanR metrics, outperforming traditional ASR-based retrieval methods that rely on transcribing speech into text for subsequent text retrieval, especially in specific scenarios.},
booktitle = {Advances in Information Retrieval: 47th European Conference on Information Retrieval, ECIR 2025, Lucca, Italy, April 6–10, 2025, Proceedings, Part IV},
pages = {10–20},
numpages = {11},
keywords = {Multimodal IR, Speech Retrieval, Contrastive Learning},
location = {Lucca, Italy}
}